参考《Redis设计与实现》
1.主从复制
主从复制的作用
-
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
-
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
-
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
-
读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量;
-
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
实现
通过slaveof命令可以实现主从辅助,被复制的服务器叫主服务器,执行复制的服务器叫从服务器,例如
127.0.0.1:6379> slaveof 127.0.0.1:12345
127.0.0.1:6379表示主服务器,127.0.0.1:12345表示从服务器,其主从服务器的数据库状态一致,在主服务器进行增删改,从服务器也会执行相应的增删改。
redis的复制分为两个操作:同步(psync)和命令传播(command propagate)
同步
同步又分为完整重同步和部分重同步
- 完整重同步用于初次处理复制的情况,步骤如下
- 从服务器向主服务器发送
psync ? -1命令 - 收到psync命令的主服务器执行bgsave,生成RDB文件,并用缓冲区记录所有写命令
- 主服务器的bgsave执行完毕后,将RDB文件发送给从服务器,从服务器接收这个RDB文件,并将数据库状态更新
- 主服务器将缓冲区里所有的写命令发送给从服务器,从服务器接收命令并更新服务器状态至主服务器数据库当前状态
- 从服务器向主服务器发送
- 部分重同步用于断线后复制情况,步骤和上述类似,不过从服务器发送给主服务器的命令是
psync <runid> <offset>,其中runid为上一次复制的主服务器id,offset为从服务器当前的偏移量,同时还有一个复制积压缓冲区,当主服务器进行命令传播时,除了会把命令发送给从服务器,还会把目录写入到复制积压缓冲区(复制积压缓冲区是定长的,默认大小为1M,所以只能保存最近的一些命令),还会给缓冲区的每个字节添加复制偏移量。如果复制积压缓冲区有数据,就不用每次都执行完整的重同步,可以节省开销
命令传播
在同步完成后,此时的主从状态是一致的,但是如果主服务器再次执行写命令时,主服务器的状态会被修改,将会导致主从不一致,所以需要命令传播,即主服务器会将自己的写命令同时发送给从服务器,从服务器执行了相同的写命令后,主从服务器会再次回到数据一致状态
心跳检测
在命令传播阶段,从服务器会以每秒一次的频率,向主服务器发送命令,主要作用有3个:
- 检测主从服务器的网络连接状态,如果主服务器超过1秒没有收到从服务器发来的心跳检测命令,说明从服务器和主服务器连接出现了问题
- 主服务器有两个配置:min-slaves-to-write和min-slaves-max-lag,分别表示可正常连接的从服务器允许的最小数量和从服务器延迟最大值,如果不符合这两个配置值,主服务器将拒绝执行写命令
- 检测命令是否丢失,如果丢失,将去复制积压缓冲区找出丢失的指令,重新执行
2.Sentinel
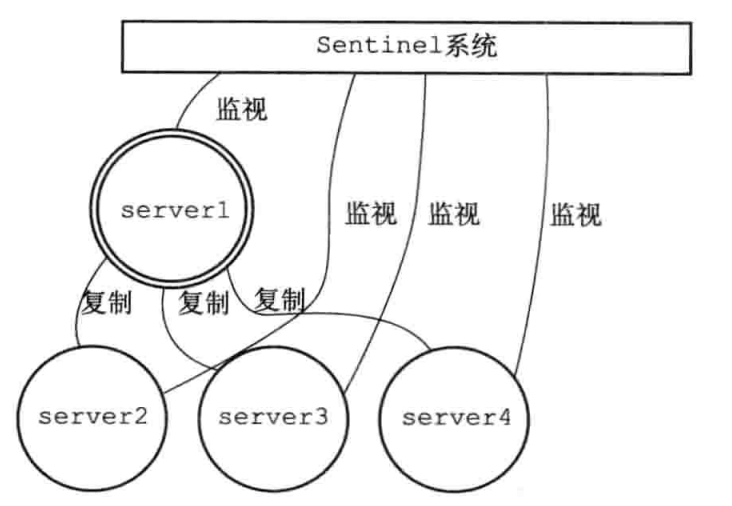
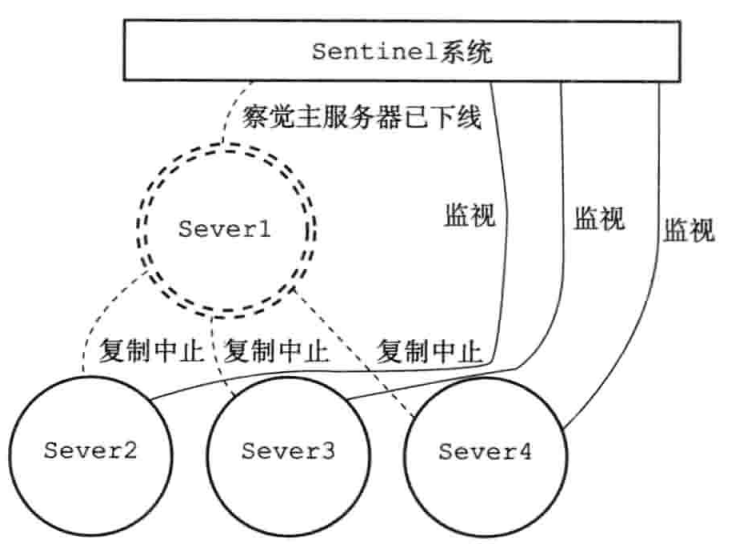
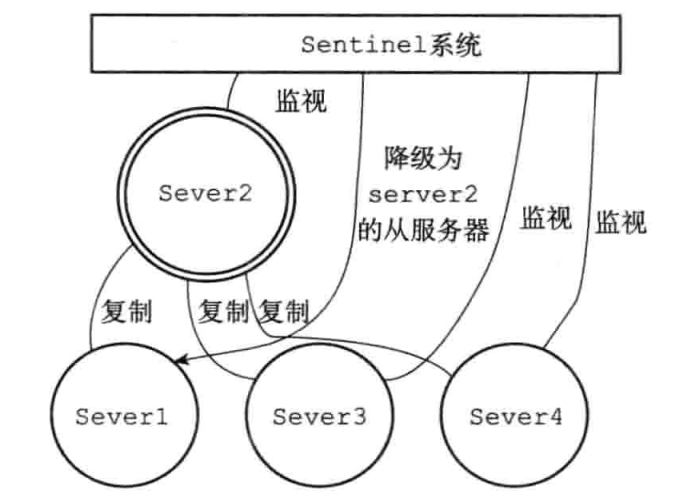
Sentinel模式(哨兵模式)是redis高可用性(高可用通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性)的解决方案:由一个或多个实例组成的sentinel系统可以监视任意多个主服务器以及其属下的从服务器,并且主服务器下线时,自动将其属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器
|
|
| 1.服务器与sentinel系统 | 2.主服务器Server1下线 |

|
|
| 3.Server1属下的其中一个从服务器升级为主服务器,sentinel继续监视Server1服务器,当Server1重新上线时,成为Server2的从服务器 | 4.Server1降级为Server2的从服务器 |
3.集群
节点
一个redis集群由多个节点(node)组成,刚开始都是独立的,只有将各个独立的节点连接起来才能形成一个集群。通过命令cluster meet <ip> <port>可以将指定的ip:port节点添加到当前node节点集群中,如下把127.0.0.1 7001、127.0.0.1 7002、127.0.0.1 7003这三个独立的节点添加节点127.0.0.1 7000所在的集群:
$redis-cli -c -p 7000 #进入端口为7000的节点
127.0.0.1:7000> cluster meet 127.0.0.1 7001
OK
127.0.0.1:7000> cluster meet 127.0.0.1 7002
OK
127.0.0.1:7000> cluster meet 127.0.0.1 7003
OK
127.0.0.1:7000> cluster nodes
884181f538839b57f8c1a87bb2283a91a9d9c8fb 127.0.0.1:7000@17000 myself,master - 0 1640615250000 2 connected
e16e3ac84ce031552407d012b079b486658ba11d 127.0.0.1:7002@17002 master - 0 1640615251000 0 connected
5861712d516c4dd9392bcab9e3c57128ef4d8c4f 127.0.0.1:7001@17001 master - 0 1640615251979 1 connected
69ddaf2f271e65865a903190fe584bd9ff7e4295 127.0.0.1:7003@17003 master - 0 1640615250969 3 connected
127.0.0.1:7000>
上述操作之前还需要配置集群环境,我参考这篇文章:搭建本地redis集群环境
槽指派
redis集群通过分片的方式来保存数据库中的键值对:集群的整个数据库分为16384个槽(slot),数据库中的每个键都属于这16384个槽的其中一个,集群的每个节点都可以处理0个或最多16384个槽,即每个节点负责一部分哈希槽
只有当数据库中的16384(0~16383)个槽都有节点在处理时,集群才能处于上线状态(ok),相反,如果数据库汇总有任何一个槽没有得到处理,那么集群都将处于下线状态(fail)
上述7000、7001、7002、7003虽然处于同一集群,但是仍为下线状态
127.0.0.1:7000> cluster info
cluster_state:fail #下线状态
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:4
cluster_size:0
cluster_current_epoch:3
cluster_my_epoch:2
cluster_stats_messages_ping_sent:3061
cluster_stats_messages_pong_sent:3137
cluster_stats_messages_meet_sent:6
cluster_stats_messages_sent:6204
cluster_stats_messages_ping_received:3137
cluster_stats_messages_pong_received:3067
cluster_stats_messages_received:6204
通过命令cluster addsolts <slot> [slot ...]可以将一个或多个槽指派给节点负责
$ redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0..5460}
OK
$ redis-cli -h 127.0.0.1 -p 7001 cluster addslots {5461..7000}
OK
$ redis-cli -h 127.0.0.1 -p 7002 cluster addslots {7001..10000}
OK
$ redis-cli -h 127.0.0.1 -p 7003 cluster addslots {10001..16383}
OK
$ redis-cli -c -p 7000
127.0.0.1:7000> cluster nodes
884181f538839b57f8c1a87bb2283a91a9d9c8fb 127.0.0.1:7000@17000 myself,master - 0 1640617981000 2 connected 0-5460
e16e3ac84ce031552407d012b079b486658ba11d 127.0.0.1:7002@17002 master - 0 1640617983512 0 connected 7001-10000
5861712d516c4dd9392bcab9e3c57128ef4d8c4f 127.0.0.1:7001@17001 master - 0 1640617982805 1 connected 5461-7000
69ddaf2f271e65865a903190fe584bd9ff7e4295 127.0.0.1:7003@17003 master - 0 1640617982300 3 connected 10001-16383
127.0.0.1:7000> cluster info
cluster_state:ok # cluster_state为ok状态,表示集群上线了
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:4
cluster_size:4
cluster_current_epoch:3
cluster_my_epoch:2
cluster_stats_messages_ping_sent:4414
cluster_stats_messages_pong_sent:4530
cluster_stats_messages_meet_sent:6
cluster_stats_messages_sent:8950
cluster_stats_messages_ping_received:4530
cluster_stats_messages_pong_received:4420
cluster_stats_messages_received:8950
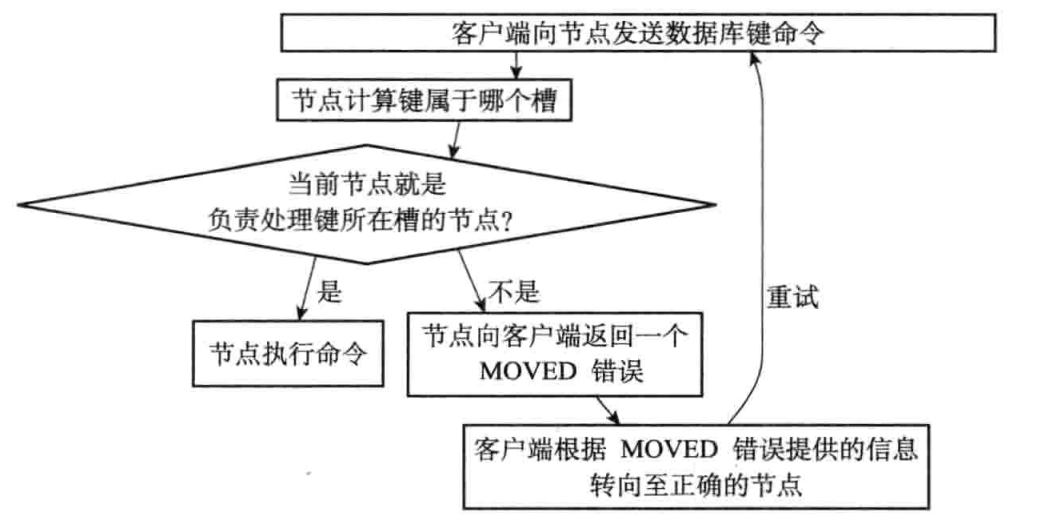
可见16384个槽都分配完了,cluster_state为ok状态,表示集群上线了,这时客户端就可以向集群中的结点发送数据了
判断键属于哪个槽是通过该公式计算出来的:CRC16(key) & 16383
127.0.0.1:7000> set key1 100
-> Redirected to slot [9189] located at 127.0.0.1:7002
OK
127.0.0.1:7002> get key1
"100"
127.0.0.1:7002> cluster keyslot "key1"
(integer) 9189
127.0.0.1:7002>
因为键key1对应的槽为9189,是7002结点负责的,所以节点7000会返回moved错误给客户端,指引客户端转向节点7002,然后客户端重新向7002结点发送set命令
重新分片
redis集群的重新分片可以将任意数量已经指派给某个节点的槽改为指派给另一个节点,且相关槽所属的键值对也会从源节点移动到目标节点,重新分片不需要下线,可以在线进行
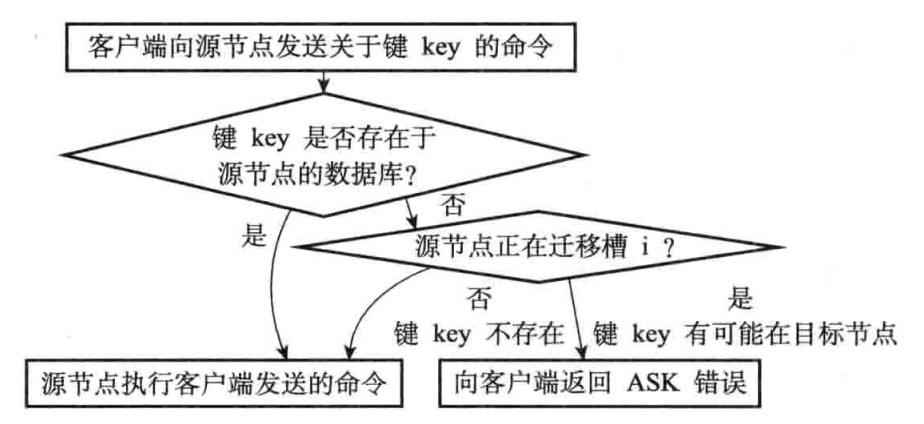
ASK错误
在重新分片的过程中,会先在自己的数据库里查找指定的键,如果源节点没能在自己的数据库找到指定的键,那么这个键有可能已经被迁移到了目标节点,源节点将向客户端返回一个ASK错误,指引客户端转向正在导入槽的目标节点,并再次发送之前想要执行的命令,注意:ASK错误的这种转向只会执行一次,除非下次再次收到ASK错误;这里和MOVED错误有区别,MOVED所指向的目标节点可以持续执行命令,直到结束
故障检测和故障转移
集群中的每个节点都会定期向集群中的其他节点定期发送ping消息,以此检测对方是否在线
当一个从节点发现自己复制的主节点下线了,就会开始故障转移,从一个从节点中新选举一个主节点,新选举主节点的方式和Sentinel模式有点类似,都是基于Raft算法的领头选举方法来实现的


...