确切的说是MySQL使用了InnoDB引擎,而InnoDB使用的B+树结构
1.各种数据结构的对比
1.1 哈希表
哈希表是一种以键-值(key-value)存储数据的结构,只要输入待查找的值即key,就可以找到其对应的值即Value,时间复杂度为O(1),但是容易发生哈希冲突,当发生冲突时,常用开放地址法、拉链法、再散列法解决
因为Value不是有序存储的,所以哈希索引做区间查询的速度是很慢的,范围查找时只能通过扫描全表的方式,所以哈希表这种结构适用于只有等值查询的场景,而不适用于范围查询
1.2 有序数组
有序数组在等值查询和范围查询场景中的性能都非常优秀,等值查询的时候可以用二分查找,时间复杂度为O(log(N));范围查询时可以先用二分查找找到第一个值,然后向右遍历。
如果仅仅看查询效率,有序数组是最好的数据结构,但是要更新数据时就必须挪动后面所有的数据,成本太高。所以有序数组索引只适用于查询的情况
1.3 红黑树
红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但其平衡的代价较低, 其平均统计性能要强于 AVL 。
| 以升序插入构建红黑树 | 以降序插入构建红黑树 | 随机插入构建红黑树 |
|---|---|---|
|
|

|
因为红黑树中每个结点都会存放一个数据,而不仅仅只起索引作用,除此之外红黑树一个结点只存放一个key,结点利用率低,而B/B+树一个结点可以存放多个关键字,在关键字总数相同的情况下,红黑树的高度总是大于B/B+树,在大规模数据存储的时候,红黑树会出现树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。
1.4 B树(B-树)
一颗m阶的B树的定义如下:
- 每个节点最多有m-1个关键字
- 根节点最少可以只有一个关键字
- 非根节点至少有⌈m/2⌉-1个关键字
- 每个节点的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的路径长度都相同
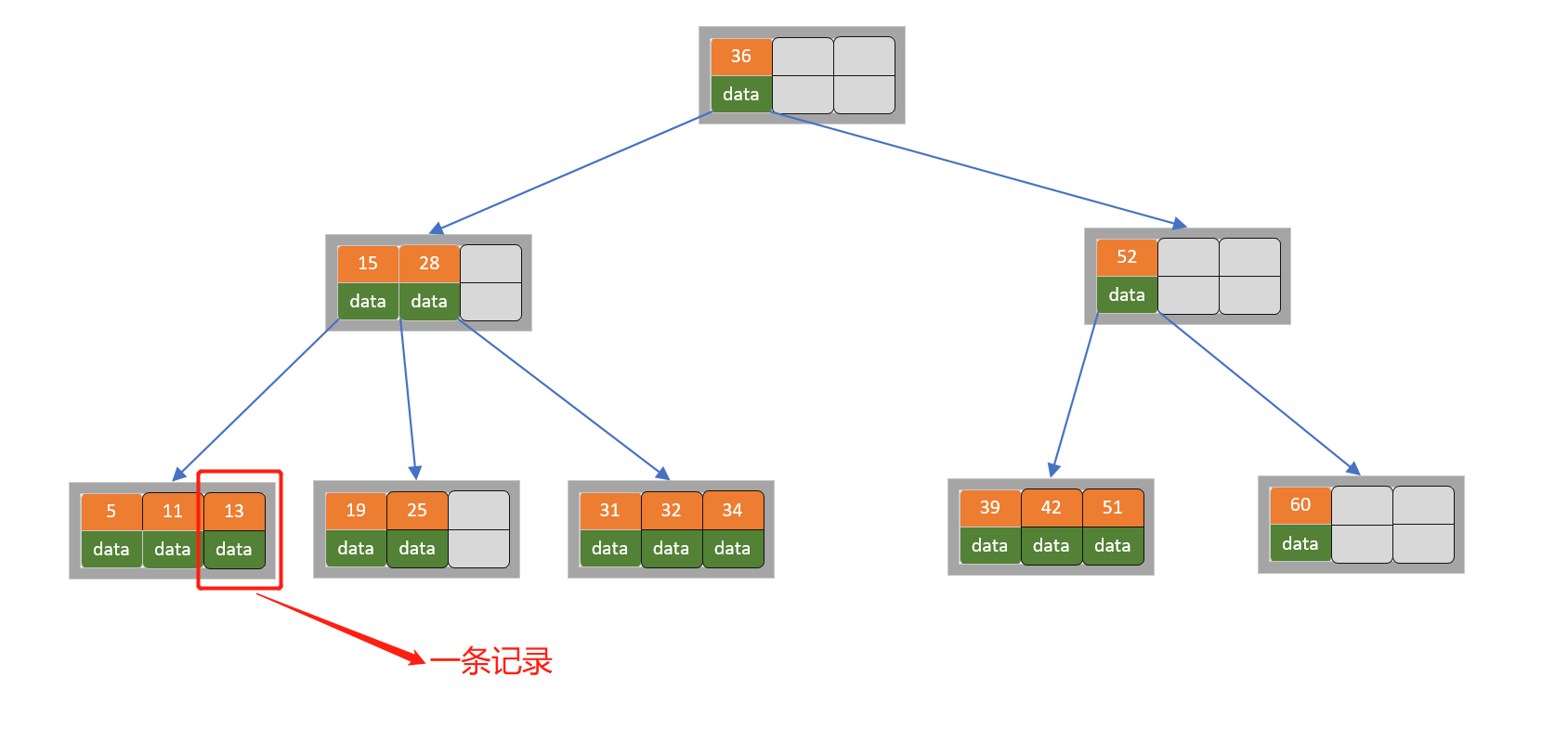
将一个key和其对应的data称为一个记录,MySQL数据库中如果以B树作为索引结构,此时上图的黄色结点key表示键,而绿色结点data表示这个键对应的条目在磁盘上的逻辑地址
1.5 B+树
B+树的特性:
- B+树包含2种类型的节点:内部节点(也称索引节点)和叶子节点。根节点本身即可以是内部节点,也可以是叶子节点。根节点的关键字个数最少可以只有1个
- B+树与B树最大的不同是内部节点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子节点中
- m阶B+树表示了内部节点最多有m-1个关键字(或者说内部节点最多有m个子树),阶数m同时限制了叶子节点最多存储m-1个记录
- 内部节点中的key都按照从小到大的顺序排列,对于内部节点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子节点中的记录也按照key的大小排列
- 每个叶子节点都存有相邻叶子节点的指针,叶子节点本身依关键字的大小自小而大顺序链接
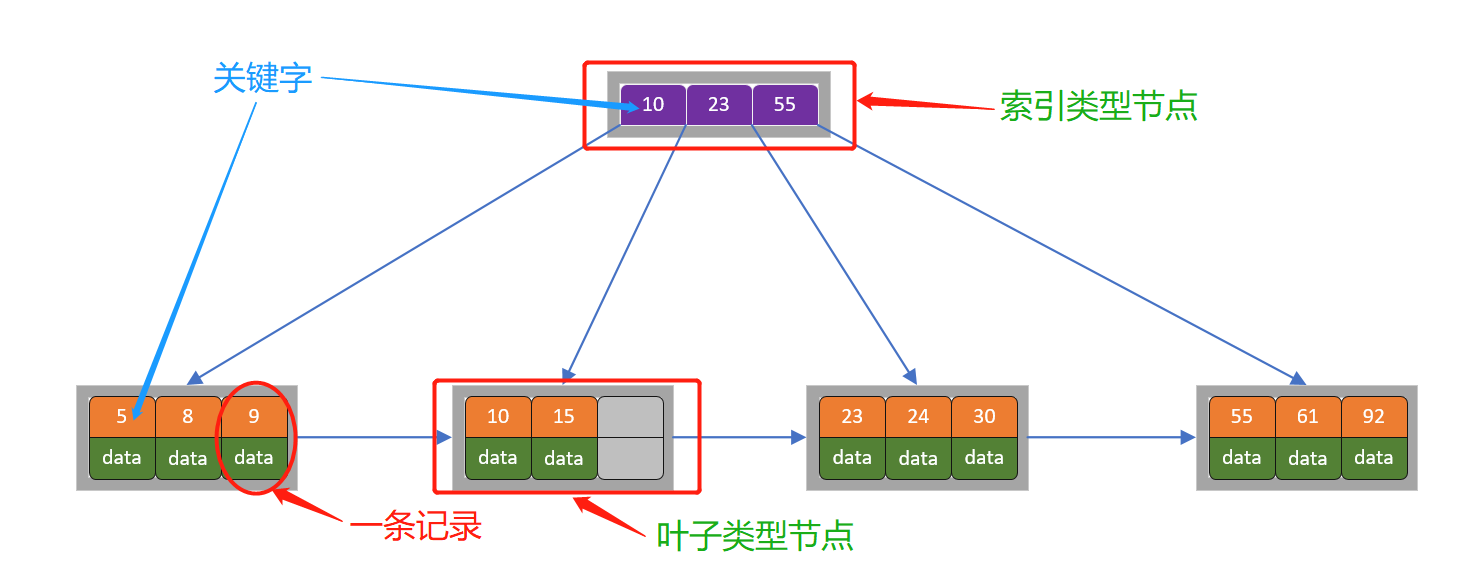
B+树因为只有叶子结点才保存数据,内部节点只是作为索引,因此一个内存页可以存放更多的key,数据的存放更加紧密,具有更好的局部性,命中率更高,查询速度更快;B+树的相邻叶子结点有指针相连,且自小而大顺序链接,所以也适合做范围查询
1.6 总结
使用B+树而不是其它数据结构的原因:
- 哈希表只适合等值查询,而不适合范围查询
- 有序数组挪动数据的成本太高
- 红黑树结点利用率低,层数高,不适合做范围查询
- B树结点除了存放索引外还会存放数据,每个内存页的利用率不如B+树,且B树做范围查询时要进行每一层的递归遍历,效率不如B+树。但B树也有优点,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速
- B+树因为只有叶子结点才保存数据,内部节点只是作为索引,所以相比于B树一个内存页可以存放更多的key,数据的存放更加紧密,具有更好的局部性,命中率更高;同时B+树的相邻叶子结点有指针相连,且自小而大顺序链接,所以也适合做范围查询,MySQL中范围查询是很频繁的,而B树不支持这样的操作导致效率太低;还有,B+树的所有value都在叶子结点,所以B+树到叶子结点的索引长度总是相等的,比B树更稳定
- 因为B树和B+树一个结点可以存放多个key或value,相比普通的二叉树整体的高度更低,可以减少磁盘IO的次数,而B+树又比B树的高度更低,所以最终选择了B+树
2.B+树在MySQL中的应用
2.1 聚簇索引
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中,“聚簇”即数据行相邻的键值紧凑的存储在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引

从上面的图可知采用了B+树的结构,因为把数据都保存在一起,这样只需从磁盘读少许的数据页就能获取大量的数据value,减少了磁盘IO。
与聚簇索引相对应的是非聚簇索引,也叫做二级索引,二级索引访问需要两次索引查找。因为二级索引叶子结点保存不是行指针,而是行的主键值,找到主键值后还要根据主键值去聚簇索引中查找对应的行
2.2 覆盖索引
覆盖索引只能通过B+树来实现,因为哈希索引、全文索引等都不存储索引列的值。覆盖索引指一个索引包含(覆盖)了所有要查询的字段的值

如上图所示,如果执行语句select * from T where k between 3 and 5,流程如下:
- 在k索引树上找到k=3的记录,取得ID=300
- 再到ID索引树查到ID=300对应的R3(第一次回表)
- 在k索引树取下一个值k=5,取得ID=500
- 再回到ID索引树查到ID=500对应的R4(第二次回表)
- 在k索引树取下一个值k=6,不满足条件,循环结束。
可见,回表了两次。而通过覆盖索引可以避免回表过程
如果执行select ID from Table where k between 3 and 5查询语句,由于用到了覆盖索引,这时只需要查ID的值,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引k已经“覆盖了”我们的查询需求,我们称为覆盖索引
2.3 自增主键
B+树为了维护索引有序性,在插入新值的时候需要做必要的维护。根据B+树的算法,为了保持B+树的平衡,当一个数据页插满后会申请一个新的数据页,然后挪动部分数据过去,称为页分裂,这个过程会影响性能,而且整体空间利用率会降低50%;当删除部分页数据后,页的利用率会降低,会做页合并操作,如果没有自增主键,频繁的页分裂和合并会导致效率变低
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页,不涉及到挪动其他记录,也不会触发叶子节点的分裂。而若有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。所以自增主键总的来说就是可以提高查询和增删的性能。
同时,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小,所以,从性能和存储空间方面考量,自增主键往往是更合理的选择
2.4 最左前缀原则
创建一个三列的联合索引包含(col1, col2, col3),索引会生效于(col1),(col1, col2)以及(col1, col2, col3)
比如以下示例:
1. SELECT * FROM tbl_name WHERE col1=val1;
2. SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
3. SELECT * FROM tbl_name WHERE col2=val2 AND col1=val1;
4. SELECT * FROM tbl_name WHERE col2=val2;
5. SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
6. SELECT * FROM tbl_name WHERE col1=val1 AND col3=val3;
-
第一条和第二条和第三条查询语句用到了索引,第二条和第三条效果是一样的,即与where语句中字段出现的顺序无关
-
第四条和第五条查询虽然包含索引的列,,但是不会用索引去执行查询,因为(col2)和(col2, col3) 不是(col1, col2, col3)的最左前缀
-
第六条查询只会执行(col1)的索引查询
若字段为字符串,则对于索引的第一个字段,用like时左边必须是固定值,通配符只能出现在右边,select * from AAA where a like '张%'会用到索引;而select * from AAA where a like '%三'不会用到索引

从上图可以看到最左前缀原则和B+树的结合 ,先按名字搜索,然后在此基础上按岁数搜索,在搜索名字的时候还可以采用给字符串添加搜索的方式,比如:where name like '张%',会找到ID3的位置,然后再匹配名字的全称,然后再匹配岁数


...