学习极客时间《分布式技术原理与算法解析》
1. 分布式概览
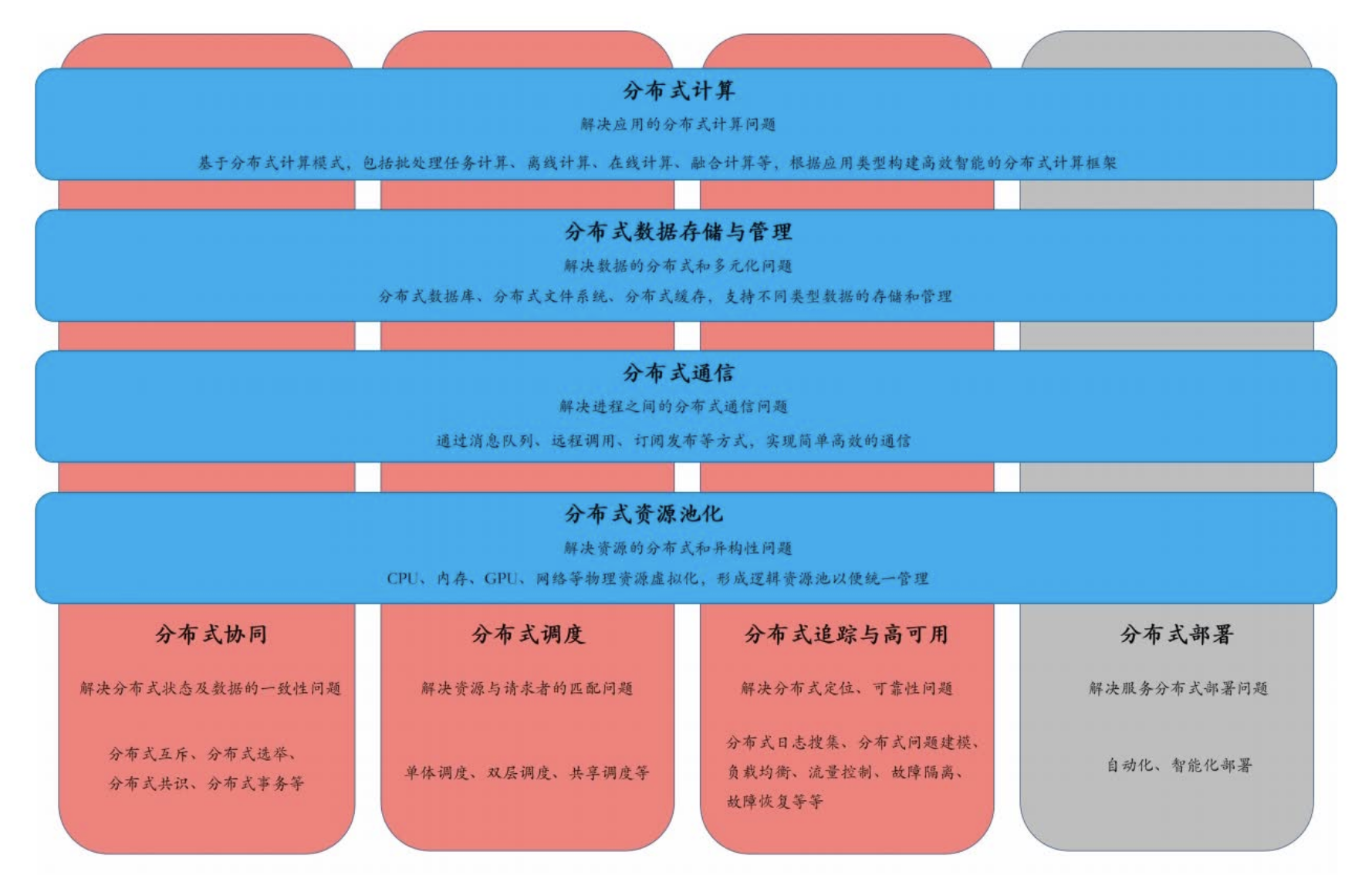
1.1 分布式知识体系图
1.2 分布式发展历程
| 单机模式 | 数据并行模式 | 任务并行模式 | |
|---|---|---|---|
| 简介 | 所有业务和数据都在一台服务器上 | 让多台服务器放同样的代码逻辑,把要执行的数据拆分后分别放到这些服务器同时执行,用空间换时间 | 把单个任务拆分成多个子任务并行执行 |
| 优点 | 便于集中管理、维护、执行 | 缩短所有任务的总体执行时间 | 能缩短单个任务的执行时间 |
| 缺点 | 单台服务器有性能瓶颈,有单点失效问题 | 对提升单个任务的执行性能及降低时延无效 | 任务拆分的复杂性增加 |
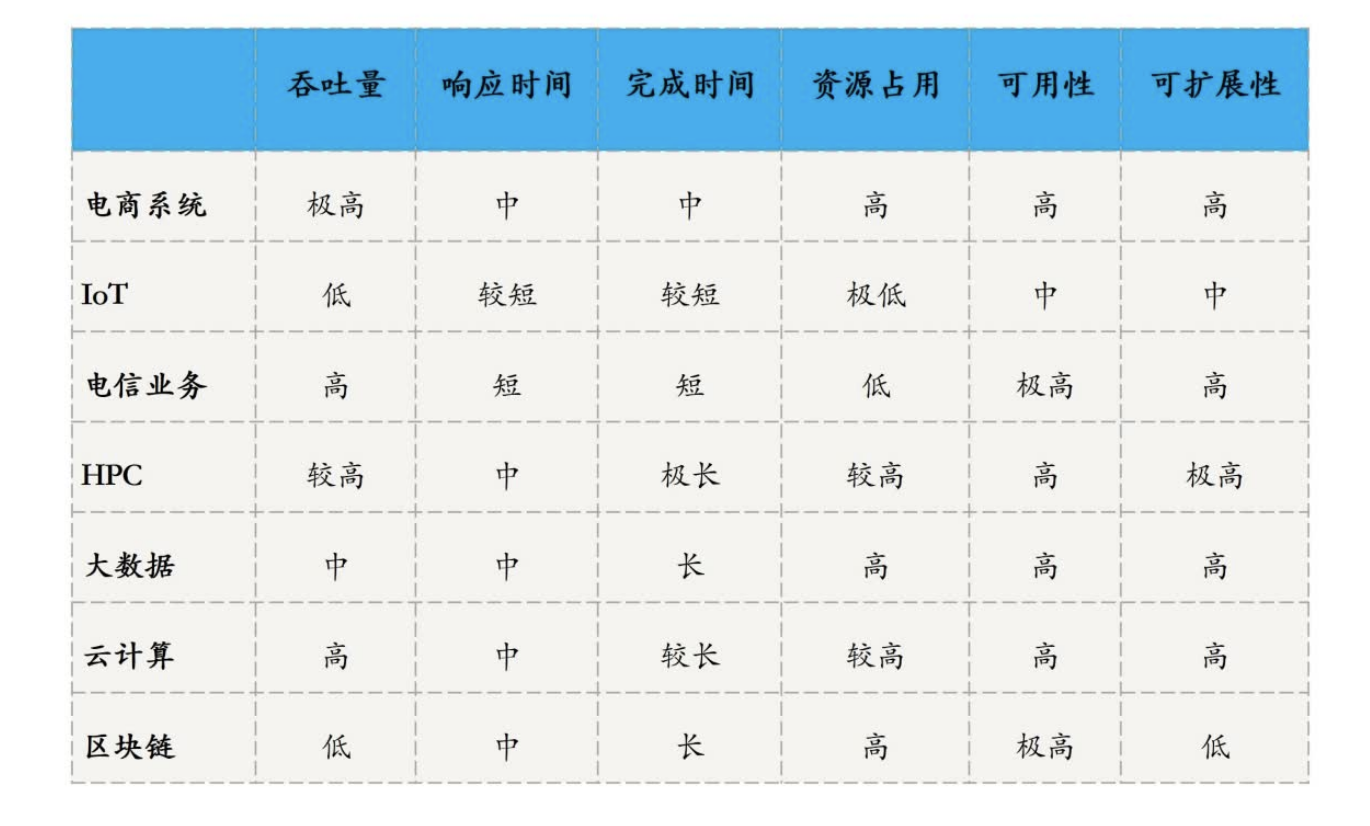
1.3 分布式系统指标
性能指标:
- 吞吐量
- QPS:每秒的查询数,常用于读操作;
- TPS:每秒处理的事务数,常用于写操作;
- BPS:每秒处理的比特数,常用于衡量数据量;
- 响应时间:系统响应一个请求所花费的时间,直接影响到用户体验
- 完成时间:系统真正完成一个请求所花费的时间
资源占用:
- 空载资源占用:系统在没有任何负载时,本身所自带的资源占用
- 满载资源占用:系统满额负载时的资源占用
可用性:
- 可用性:系统面对各种异常情况时依然可以正确提供服务的能力,体现了系统的鲁棒性,可用(正常运行时间/总运行时间) 的比值来判断可用性高低,表示可以允许系统出现部分故障的情况下,仍能对外提供服务的能力。
- 可靠性:通常表示一个系统完全不出故障。
可扩展性:有横向的集群数量扩展,也有纵向的单机性能扩展。
不同场景下的指标要求:
2. 分布式互斥与同步
2.1 分布式互斥
在分布式系统里,访问临界资源,就叫分布式互斥;临界资源就是被互斥访问的共享资源。
分布式互斥方法:
| 集中式方法 | 分布式方法 | 令牌环方法 | |
|---|---|---|---|
| 描述 | 通过协调者,把所有请求放入队列,按FIFO的方式请求临界资源 | 每个请求者使用临界资源时,都要征求其他参与者的同意 | 所有参与者组成环,令牌顺/逆时针流动,拿到令牌的参与者则可访问临界资源 |
| 优点 | 简单、通信高效、易实现 | 可用性高 | 单个参与者通信效率高,因为不用请求其他参与者同意 |
| 缺点 | 瓶颈在协调者,可用性低 | 通信成本高、复杂度高 | 容易造成无用通信,例如一轮下来,只有几个参与者需要访问令牌 |
| 场景 | 在协调者稳定性高的情况下适合使用 | 系统规模小或使用频度低的情况下 | 系统规模小、每个参与者使用临界资源的频率高的情况下 |
2.2 分布式选举
分布式选举主要是选出主节点,该主节点在分布式集群中对其他子节点进行协调和管理,保证集群有序运行和节点间数据的一致性。
| Bully算法 | Raft算法 | ZAB算法 | |
|---|---|---|---|
| 描述 | 遵循长者为大的原则,即在所有活着的节点中,选取 ID 最大的节点作为主节点 | 少数服从多数原则,获得投票最多的节点成为主节点(超过半数即可为leader) | ZAB协议是专门为zookeeper实现分布式协调功能而设,遵循少数服从多数,ID 大的节点优先为主的原则,可以看成对Raft算法的改进 |
| 选举过程 | Election消息:用于发起选举,如p1->p2发送选举消息,表示p1支持选举p2当Leader。 Alive消息:若本节点收到比自己 ID 小的节点发送的 Election 消息,则回复一个 Alive 消息,告知其他节点,我比你大,重新选举。 Victory消息:若在给定的时间范围内,本节点没有收到其他节点回复的 Alive 消息,则认为自己成为主节点,并向其他节点发送 Victory 消息,宣誓自己成为主节点。 |
Follower状态:开始时所有节点都是Follower状态,Follower 节点会定期发送心跳包给Leader节点,以检测主节点是否活着。 Candidate状态:开始选主时所有Follower转为Candidate状态,发送选举请求,每个节点只有一次投票权。 Leader状态:发起选举请求的节点获得超过一半的投票,变为Leader状态。Leader任期到了,会降为Follower状态,参与新一轮选举。 |
Looking 状态,即选举状态。当节点处于该状态时,它会认为当前集群中没有 Leader,因此自己进入选举状态。 Leading 状态,即领导者状态,表示已经选出主,且当前节点为 Leader。 Following 状态,即跟随者状态,集群中已经选出主后,其他非主节点状态更新为Following,表示对 Leader 的追随。 Observing 状态,即观察者状态,表示当前节点为 Observer,持观望态度,没有投票权和选举权。 |
| 优点 | 简单、快速、复杂度低、易实现 | 快速、复杂度低、易实现 更稳定,当有新节点加入时会触发选主,但不一定能拿到超过一般的票数而切主。 |
稳定性好,当有新节点加入时会触发选主,但不一定能拿到超过一般的票数而切主。 算法性能高 |
| 缺点 | 因为需要每个节点有全局信息,所以额外信息存储较多。 只要随便新进来一个ID比当前leader的ID大的,就会易主,所以导致容易频繁易主。 不适合大规模分布式系统。 |
因为要求所有节点都可以互相通信且要参与投票,所以导致通信量大、连接数多,不适合大规模集群 | 因为采用广播方式发送消息,当节点多的时候容易发生广播风暴。 选举时间长 复杂度高 |
| 场景 | 适用于小规模分布式系统 | 适合中小规模场景 | 适合大规模分布式系统 |
为什么选举算法常采用奇数个节点?
因为偶数个节点容易出现两个主的情况,造成重新选主,而且第二次选主依然有概率出现两个主的情况。
2.3 分布式共识
分布式共识:分布式共识就是在多个节点均可独自操作或记录的情况下,使得所有节点针对某个状态达成一致的过程。比如通过分布式共识,使得分布式系统中不同节点的数据达成一致。
分布式共识比较常用与区块链技术中。比如有5台服务器,其中一台进行了金钱转账,那么如何让另外4台服务器也达到一样的状态呢?这就是分布式共识要解决的问题。在分布式在线记账问题中,针对同一笔交易,有且仅有一个节点或服务器可以获得记账权,然后其他节点或服务器同意该节点或服务器的记账结果,达成一致。也就是说,分布式共识包括两个关键点,获得记账权和所有节点或服务器达成一致
分布式共识方法:
| PoW | PoS | DPoS | |
|---|---|---|---|
| 全称 | Proof-of-Work 工作量证明 |
Proof-of-Stake 权益证明 |
Delegated Proof of Stake 委托权益证明 |
| 过程 | 每个节点都去解同一道题目,哪个节点先得出正确答案,就获得记账权,简单来说:谁的计算能力强,获得记账权的可能性就越大 | 由系统权益代替算力来决定区块记账权,拥有的权益越大获得记账权的概率就越大 | 相比于 PoS 算法,DPoS 引入了受托人,由投票选举出的若干信誉度更高的受托人记账,解决了所有节点均参与竞争导致消息量大、达成一致的周期长的问题。 |
| 优点 | 去中心化、安全性高 | 解决了Pow算法的问题,效率高 | 解决了 PoS 算法的垄断问题,能耗更低,速度更快 |
| 缺点 | 如果题目过难,则计算时间过长,导致资源浪费;如果题目过于简单,会导致大量节点获取记账权,导致冲突。总结来说就是达成共识的时间长,效率偏低。 | 去中心化程度和安全性不如PoW,易造成垄断 | 去中心化程度不如前面的两种算法,投票积极性不高 |
| 场景 | 比特币 | 以太坊 | 以太股 |
2.4 分布式事务
分布式事务就是在分布式系统中运行的事务,由多个本地事务组合而成,都要遵循ACID原则。
2.4.1 二阶段提交法
准确来说是基于XA协议的二阶段提交法
XA协议:分为两部分,即事务管理器和本地资源管理器。事务管理器作为协调者负责各个本地资源的提交和回滚;资源管理器就是分布式事务的参与者,通常由数据库实现。
为了保证事务的一致性,需要引入一个协调者来管理所有节点,分为投票阶段和提交阶段。
| 阶段 | 过程 |
|---|---|
| 投票阶段 | ① 协调者发送请求给参与者,询问是否可以执行提交(commit)操作。 ② 参与者收到请求后,会执行请求中的事务操作,并将undo信息和redo信息写入事务日志,但不提交(commit)。若执行成功,会返回yes;若执行失败,会返回no。 ③ 协调者等待所有参与者返回操作结果后进入提交阶段。 |
| 提交阶段 | 情况一,协调者收到的都是yes: ① 协调者向所有参与者发送正式 commit 的请求 ② 参与者完成操作后释放占用的资源 ③ 参与者向协调者返回“ack完成”消息 ④ 协调者收到所有参与者的回复后意味着这个事务结束了 情况二,协调者收到的信息中存在no: ① 协调者向所有参与者发送 rollback 请求 ② 参与者收到 rollback 消息后利用之前的undo日志执行回滚 ③ 参与者回滚完后释放占用的资源 ④ 参与者向协调者恢复 ack回滚完成 信息 ⑤ 协调者收到所有参与者的回复后,取消事务 |
存在的问题 :
① 同步阻塞问题。因为所有节点都是事务阻塞型,所有只要有一个节点在访问临界资源时,其他节点只能等待,只有协调者有超时机制,参与者没有超时机制
② 单点故障问题。一旦某个节点发生故障,则会锁定事务资源,其他节点也会处于等待状态,导致整个系统阻塞
③ 数据不一致问题。在提交阶段,在协调者向参与者发送提交请求后,若因为网络或其他原因导致只有部分参与者接收到了请求并执行,于是就会出现数据不一致的问题
2.4.2 三阶段提交法
三阶段提交是在二阶段提交的基础上,中间加了一个预提交阶段,改善了同步阻塞问题和数据不一致问题。
因为引入了超时机制,所以不管是协调者阻塞还是参与者阻塞,只要超过了一定时间都会自动释放,虽然没有完全消灭阻塞,但是缩短了阻塞时间。
因为有了预提交阶段,在预提交阶段就会先判断是否所有参与者都能提交事务,再到正式提交阶段正式执行提交,可以有效解决数据不一致问题。
| 阶段 | 过程 |
|---|---|
| 投票阶段 | 协调者向参与者发送请求,询问是否可以执行事务操作,参与者回复yes或no |
| 预提交阶段 | 情况一,协调者收到的都是yes: ① 协调者向参与者发送预提交请求,进入预提交阶段 ② 参与者接收到请求后执行事务操作,并记录undo日志和redo日志 ③ 若参与者成功执行了事务,则返回 ack成功 信息 情况二,协调者收到的信息中存在no: ① 协调者向所有参与者发送中中断请求 ② 参与者接收到中断请求后,或超时仍未接收到协调者的信息,执行事务的中断操作 |
| 提交阶段 | 情况一:正式提交阶段: ① 协调者接收到所有参与者的 ack成功 响应后,向参与者发送正式提交消息 ② 参与者收到协调者的正式提交消息后,正式提交事务,完成后释放锁住的资源 ③ 参与者提交完事务后,向协调者回复 ack 响应 ④ 协调者收到所有参与者的响应后,表示完成事务 情况二:事务中断阶段: ① 协调者向所有参与者发送回滚请求 ② 参与者收到回滚消息后,利用预提交阶段记录的undo日志进行事务的回滚,并释放事务资源 ③ 参与者回滚完成想协调者回复ack消息 ④ 协调者收到参与者回滚完成的消息后结束事务 |
在预提交阶段,参与者根据什么返回 Yes 或者 No 消息呢?参与者会根据自身情况,比如自身空闲资源是否足以支撑事务、是否会存在故障等,预估自己是否可以但不执行事务,参与者根据预估结果给协调者反回 Yes 或者 No 消息。
2.4.3 最终一致性方案
二阶段提交和三阶段提交都存在两个问题:① 处理事务时都需要锁定资源。② 仍然存在数据不一致的问题。
所以提出了最终一致性的方案,准确来说是基于消息队列的最终一致性方案。这个消息队列用于在多个节点之间传递消息,因为消息队列本身具有存储功能,所以可以用来存储消息和日志。
大致思想如下:
① 生产者可以向消息队列发送具体的消息
② 消息队列把消息存起来,然后异步发送给消费者
③ 消费者收到消息后可以异步执行各自的具体事务,不管是执行成功还是失败都要给消息队列返回响应
④ 若消息队列收到了某个消费者返回执行成功的消息,表示这个消费者完成了任务
⑤ 若消息队列收到了某个消费者返回执行失败的消息,则消息队列会继续给这个消费者发送消息,即失败重试
⑥ 当所有消费者都完成事务后,才会删除消息队列里的消息,即最终一致性
2.4.4 总结
| 刚性事务 | 柔性事务 |
|---|---|
| 如二阶段提交和三阶段提交 | 如最终一致性方案 |
| 遵循ACID原则 | 遵循BASE理论, BASE 理论包括: ① 基本可用(Basically Available) ② 柔性状态(Soft State) ③ 最终一致性(Eventual Consistency) |
| 缺点: ① 数据不一致问题 ② 性能低 ③ 吞吐量一般 优点: ① 强一致性 ② 同步执行 ③ 算法实现简单 ④ 三阶段提交解决了二阶段提交同步阻塞问题和单点故障问题 |
缺点: ① 算法复杂度高 优点: ① 最终一致性 ② 异步执行 ③ 性能高 ④ 吞吐量高 ⑤ 无同步阻塞问题 ⑥无单点故障问题 |
2.5 分布式锁
锁是实现多线程访问同一共享资源,保证同一时刻只有一个线程可访问共享资源所做的一种标记。分布式锁处于分布式环境中,具有多个服务器,实现分布式互斥。为了保证多个进程可以看到锁,一般把锁存放在公共存储中(如redis、数据库等)。
分布式锁应该具有这些特征:
- 互斥性:只能有一个客户端持有锁
- 超时释放:防止死锁
- 可重入:一个线程获取锁后,可以再次加请求加锁,更新过期时间等
- 高性能、高可用:使开销尽可能低,可用性高
- 安全性:锁只能被持有的客户端删除,不能被其他客户端删除
2.5.1 基于数据库
关于mysql锁的介绍,我写过一篇文章:
- 基于数据库的增删
- 这是最简单的一种方式,即在数据库创建一张专门用于存放锁标记的锁表。当某个请求(A)对数据库的某个共享资源操作时,就往锁表增加一条记录,表示锁住了该资源,当操作完成后,就删除这条记录,表示释放锁。其他请求(B)想要操作该资源时都要先查询锁表,看是否有请求在操作该共享资源,如果有,就要等待,否则往锁表插入记录,表示请求(B)锁定了该资源。
- 优点:容易理解、复杂性低
- 缺点:单点故障,容易导致整体系统崩溃;死锁问题,锁没有限定失效时间;数据存放在磁盘,有IO读写开销,操作数据库开销大
- 基于数据库的排它锁
- 即在执行语句的时候添加
for update,如:select ... from ... for update,当加上排它锁的时候,其他事务不能加锁
- 即在执行语句的时候添加
基于数据库的分布式锁适合于并发量低的场景
2.5.2 基于Redis
redis是基于内存的,所以数据都存放在内存中,不需要写入磁盘,减少了IO操作。
如下是几种Redis实现分布式锁的方案:
-
SETNX + EXPIRE
SETNX是(set if not exists)的缩写,如果 key不存在,则SETNX成功返回1,如果这个key已经存在了,则返回0。EXPIRE则是设置过期时间,防止死锁。
if nx := redis.SetNX("lock_key", "lock_value", 0); nx.Val() == true { // 加锁 redis.Expire("lock_key", 100) // 设置过期时间 // todo 执行业务逻辑 redis.Del("lock_key") // 释放锁 }缺点:setnx和expire两个操作是分开的,不是原子性操作,如果执行完setnx后出现了故障,那么就没法设置过期时间,锁就得不到释放,导致死锁。
-
SET扩展参数
为了解决不是原子性执行的问题,Redis 作者加入了 set 指令的扩展参数,使得 setnx 和 expire 指令可以一起执行,解决了上述问题。
SET key value[EX seconds][PX milliseconds][NX|XX]/* 从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改: EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。 PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。 NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。 XX :只在键已经存在时,才对键进行设置操作。 */ // 根据官方说法 // 因为 SET 命令可以通过参数来实现 SETNX 、 SETEX 和 PSETEX 三个命令的效果, // 所以将来的 Redis 版本可能会废弃并最终移除 SETNX 、 SETEX 和 PSETEX 这三个命令。 // 根据 go-redis 的源码 // // Redis `SET key value [expiration] NX` command. // Zero expiration means the key has no expiration time. func (c *cmdable) SetNX(key string, value interface{}, expiration time.Duration) *BoolCmd { var cmd *BoolCmd if expiration == 0 { // Use old `SETNX` to support old Redis versions. cmd = NewBoolCmd("setnx", key, value) } else { if usePrecise(expiration) { cmd = NewBoolCmd("set", key, value, "px", formatMs(expiration), "nx") } else { cmd = NewBoolCmd("set", key, value, "ex", formatSec(expiration), "nx") } } c.process(cmd) return cmd } // 因此用go语言实现该方案的写法为 if nx := redis.SetNX("lock_key", "lock_value", 100); nx.Val() == true { // 加锁并设置过期时间,为原子操作 // todo 执行业务逻辑 redis.Del("lock_key") // 释放锁 }上面两种方案都有可能出现超时问题,即业务执行时间超出了锁的超时限制,这个时候锁释放了,但是业务逻辑还在执行,其他线程可以拿到锁,导致数据被修改
还可能导致锁的误删除,如线程a执行完后即将要释放锁时,却提前被线程b占有了锁,此时线程a不知道,就把线程b的锁释放掉了,但此时线程b的业务都还没有执行完。
-
SET扩展参数 + 校验唯一随机值 + Lua脚本
为了解决在释放锁之前容易被其他线程拿到锁并被误删的问题,可以为 value 参数设置为一个随机数,释放锁时先匹配随机数是否一致,然后再删除 key。
if nx := redis.SetNX("lock_key", "lock_value", 1000); nx.Val() == true { // 加锁并设置过期时间,为原子操作 // todo 执行业务逻辑 if redis.Get("lock_key").Val() == "lock_value" { // 判断是不是当前线程加的锁,是才释放 redis.Del("lock_key") // 释放锁 } }但是匹配 value 和删除 key 不是一个原子操作,Redis 也没有提供类似于 delifequals 这样的指令,这就需要使用 Lua 脚本来处理了,因为 Lua 脚本可以保证连续多个指令的原子性执行。
if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end;
当然还有很多算法和方法用于实现redis分布式锁,如Redlock和Java中的Redisson,本文暂不讨论。
优势:
- 避免了频繁磁盘IO
- 可用集群部署,避免了单点故障
- 适合高并发场景
缺点:
- 容易时间超时而不正确释放锁
2.5.3 基于ZooKeeper
暂时不讨论,打算以后专门出一篇文章学习ZooKeeper。
3. 参考
极客时间《分布式技术原理与算法解析》


...