一.场景描述
1.场景
假设现在有5台服务器,然后有10万份的文件数据,想这些文件平均的分布在5台服务器上,平均每台2万份,用来分摊缓存压力。如果仅仅只是直接把文件分布在这5台服务器,自然是可以的,但是当要读取文件的时候,需要访问这5台服务器,因为不知道某个文件具体放在了哪台服务器,这就导致了效率低下,也没有起到缓存的作用了。
2.解决办法
解决访问效率低下的方法就是使用hash算法。首先我们知道hash算法经过hash函数后,可以直接映射到目标,所以在上述场景中,让每一个文件缓存项都有一个键,然后对键进行hash计算,然后对服务器的台数进行求模,可以决定这个文件缓存项存放在哪一台服务器,这样当要访问某一个文件时,直接通过其键值就能找到对应的文件存储服务器,而不用访问其它服务器。
3.提出问题
上面虽然解决了访问效率的问题,但是当服务器的台数增加或减少时,之前缓存的位置都会失效,造成缓存雪崩,于是会对服务器造成极大的压力,甚至崩溃,于是有了一致性hash算法。
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题。一致性hash修正了CARP使用的简单hash算法带来的问题,使得DHT可以在P2P环境中真正得到应用,但现在一致性hash算法在分布式系统中也得到了广泛应用。
二.一致性哈希算法工作原理
一致性hash算法也是采用取模的方式,但不是对服务器台数取模,而是对2^32取模,范围是0 ~ (2^32-1),然后将 2^32-1 这个区间首尾连接抽象成一个环并将节点的哈希值映射到环上,当我们要查询 key 的目标节点时,同样的我们对 key 进行哈希计算,然后顺时针查找到的第一个节点就是目标节点。
这里的节点可以看成是上述提到的服务器的映射,计算方法为 hash(服务器ip地址) % 2^32,
这里的白色的点可以看成是文件缓存项的映射,计算方法为 hash(文件的键) % 2^32,
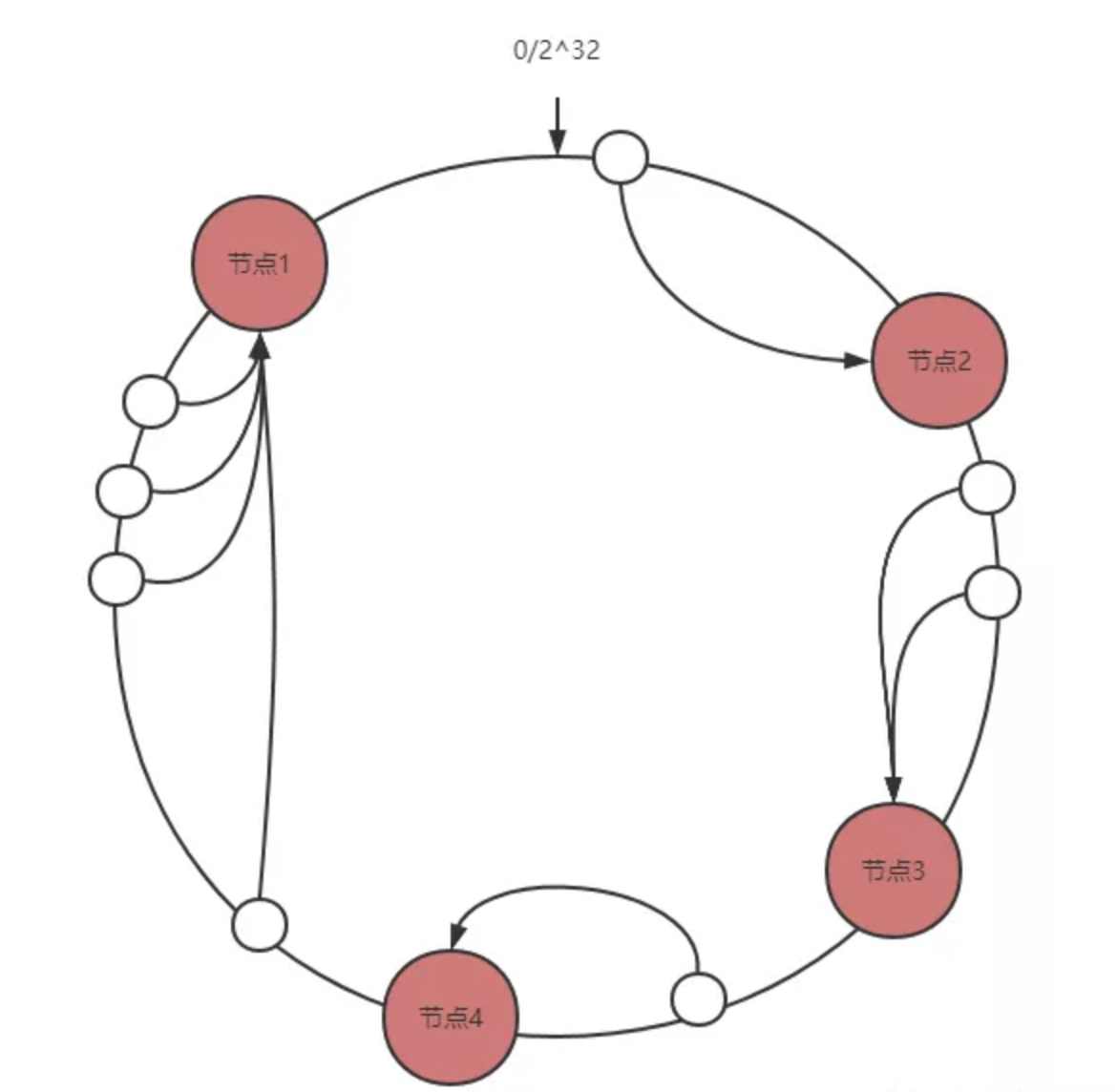
现在服务器和文件都映射到hash环上了,那么文件是怎么知道要存放到哪台服务器呢?其实是按顺时针的方式,文件对象遇到的第一个服务器节点就是他要存放的服务器,这样只要服务器不变,文件就会缓存到固定的服务器上。
1.节点添加
如果在节点4后面添加一个节点5,相当于增加一台服务器,那么此时还会造成缓存雪崩吗?其实不会的,他只会影响节点5按逆时针方向数相邻的第一个文件节点,并不会对其他文件节点造成影响,所以这就是一致性算法的优点,只会影响局部,而不会影响整体。

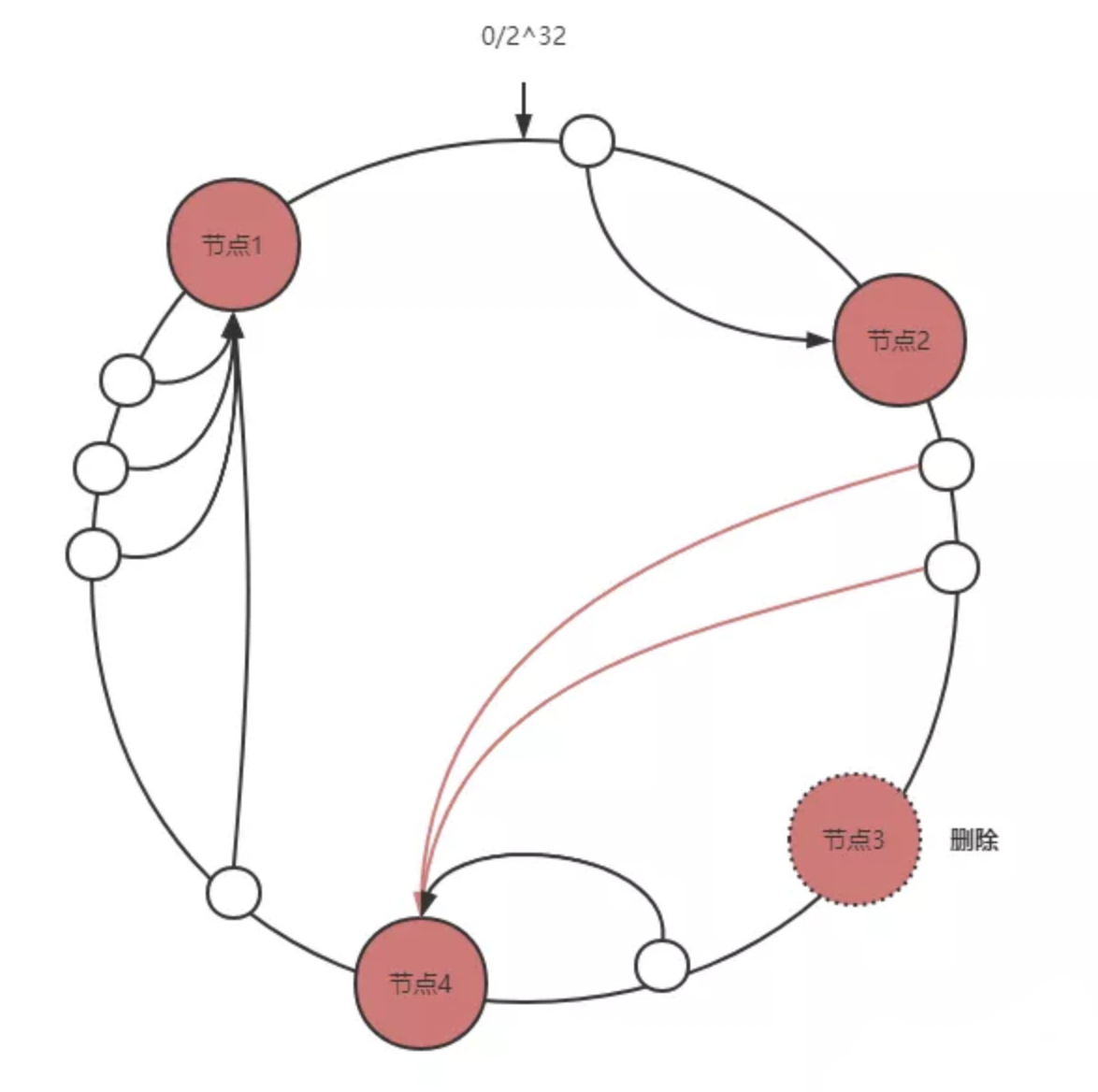
2.节点删除
节点删除只会影响删除结点和逆时针数第一个结点之间的文件对象,让这一部分数据重新存储在顺时针数第一台服务器,同样只会影响局部数据,体现了hash一致性的优点。
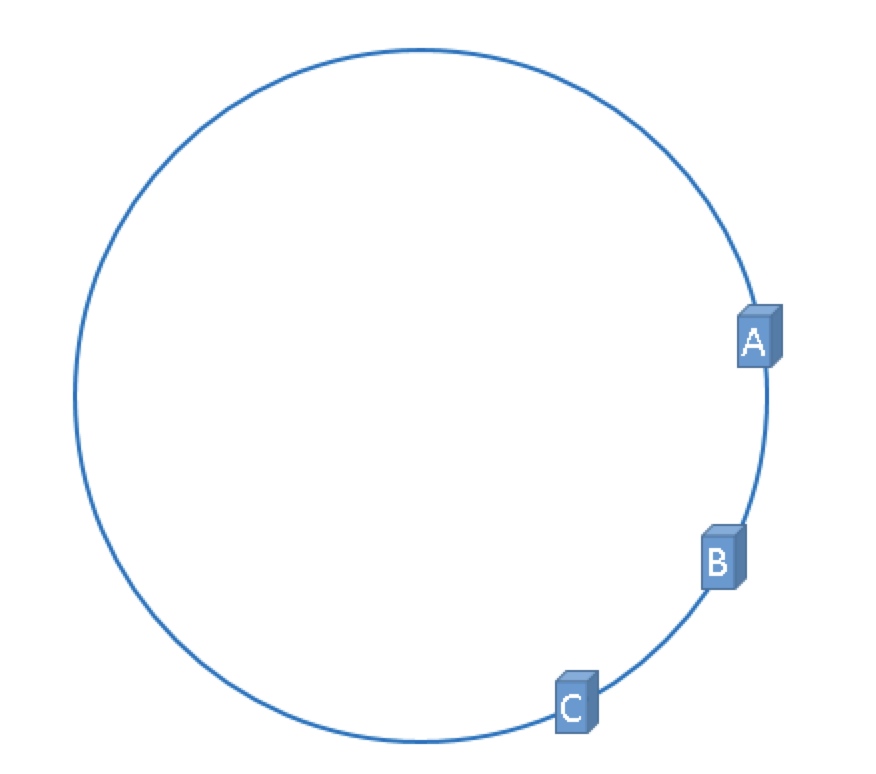
3.hash环的偏斜
在上述介绍一致性hash概念的时候,是理想化的把节点均匀的分布在了hash环上,但在实际情况下,可能会出现服务器节点集中在某一处的情况,这可能会造成某些服务器负载过大,而另一些却几乎没什么负载,如下图中的A服务器。这就会导致服务器没有被合理的平均充分利用。
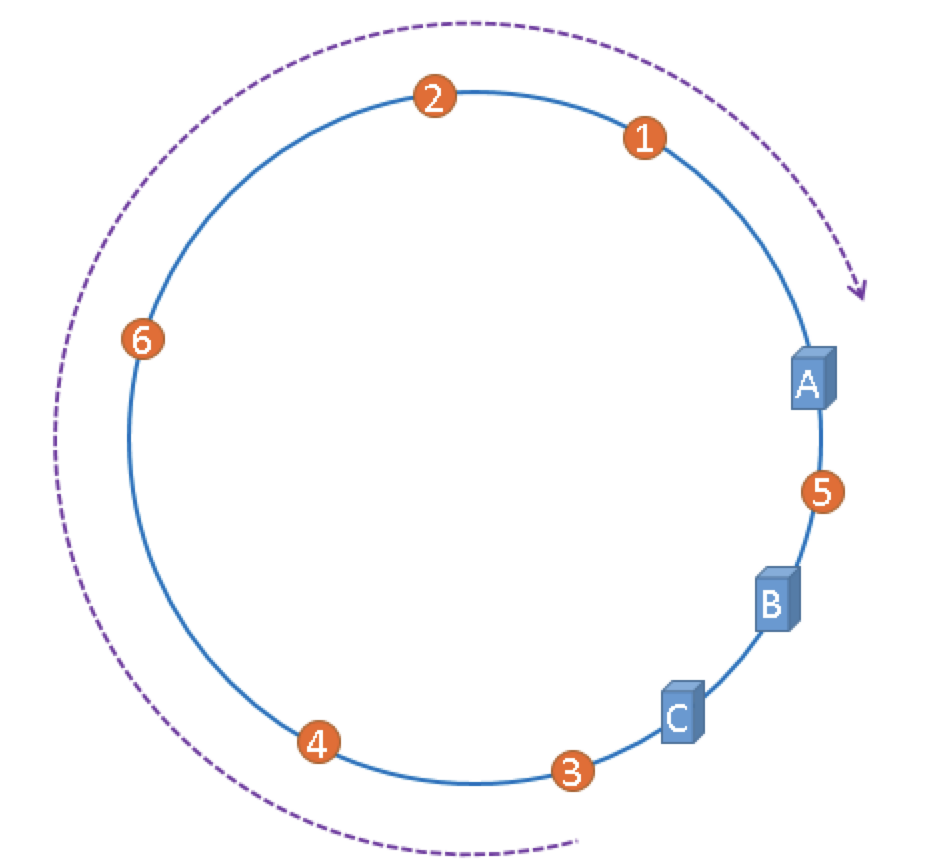
4.解决hash环的偏斜
一致性hash算法中解决hash环的偏斜采用的是“虚拟节点”的方式。即一个真实节点对应多个虚拟节点,引入虚拟节点后,可以使节点在hash环上的分布更均匀,以便减小hash环偏斜所带来的影响,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大。将虚拟节点的哈希值映射到环上,查询 key 的目标节点只需先查询虚拟节点再找到真实节点即可。



...